데이터의 정제
데이터로부터 원하는 결과나 분석을 얻기 위해서 수집된 데이터를 분석의 도구 또는 기법에 맞게 다듬는 과정이 필요
데이터 정제 방법
- 제거
- 결측치 제거: `df.dropna()`
- 컬럼/행 제거
- 이상치 제거
- 집계
- 데이터의 요약 / 통계 데이터 확인
- 데이터 특성 파악
- 일반화
- 데이터의 일반적인 특성이나 패턴을 추출
- 일관된 분석 및 예측이 가능하도록
- 정규화
- 일정한 범위로 조정해서 데이터 간의 상대적인 크기 차이를 제거하여 데이터를 표준화하는 작업
- 데이터의 상대적인 비교를 용이하게 하고, 이상치에 대한 영향을 완화시킨다
- 평활화
- 데이터의 변동을 줄이고 노이즈를 제거한다.
- 데이터의 추세나 패턴을 부드럽게 만든다.
결측치 제거
결측치 확인
- df.info() 로 전체 행의 수와 non-null값을 확인해서 결측치 개수 확인
- df.isna().sum()으로 각 인덱스마다 몇 개의 결측치가 있는지 한 눈에 확인
결측치 처리
1) 임의 제거 (`dropna`)
df.dropna(subset=['컬럼명'], how=' ', inplace=True)- df.dropna(how='any'): NaN이 하나라도 있으면 삭제
- df.dropna(how='all'): 모두 NaN인 행만 삭제
❗`df.drop(columns='컬럼명')` 에서는 columns를 사용 → 컬럼을 제거하는 것이기 때문에
❗`df.dropna(subset='컬럼명')` 에서는 subset 사용 → 특정 컬럼 안의 결측치를 제거하는 것이기 때문에
# payment컬럼에서 결측치 제거
df=df['payment'].dropna() #ver1
df=df.dropna(subset=['payment']) #ver2
# 두가지 이상의 컬럼에서 모두 결측치가 있는 행만 제거
df.dropna(subset=['pickup_borough', 'dropoff_borough'], how='all', inplace=True)
2) 임의 대체 (`fillna`)
결측치 대체 방법
- 평균 대치법: 데이터의 평균으로 결측치 대체
- 회귀 대치법: 결측치를 다른 데이터와 회귀분석을 통해 대체
- 단순확률 대치법: 확률추출에 의해 전체 데이터 중 무작위로 추출
- 최근접 대치법: 응답자료를 순서대로 정리한 후, 결측치 바로 이전/이후의 응답으로 대체(ffill,bfill)
# dropoff_borough 대해서 pickup_borough 값으로 대체
# 이전값/이후값으로 대체
# 최빈값으로 대체
df['dropoff_borough'].fillna(df['pickup_borough'], inplace=True)
df['dropoff_borough'].fillna(method='ffill',inplace=True)
df['dropoff_borough'].fillna(method='bfill',inplace=True)
df['dropoff_borough'].fillna(df['dropoff_borough'].mode()[0], inplace=True)이상치 처리
- IQR(Interquartile Range)
- 중간 50% 데이터의 범위 (Q3-Q1)
- 이상치: IQR을 기준으로 1.5배 IQR범위를 벗어난 데이터
- Z-score
- 표준화 스코어; 평균에서 얼마나 떨어져 있는지를 지표화
- 이상치: 절대값이 3보다 큰 데이터
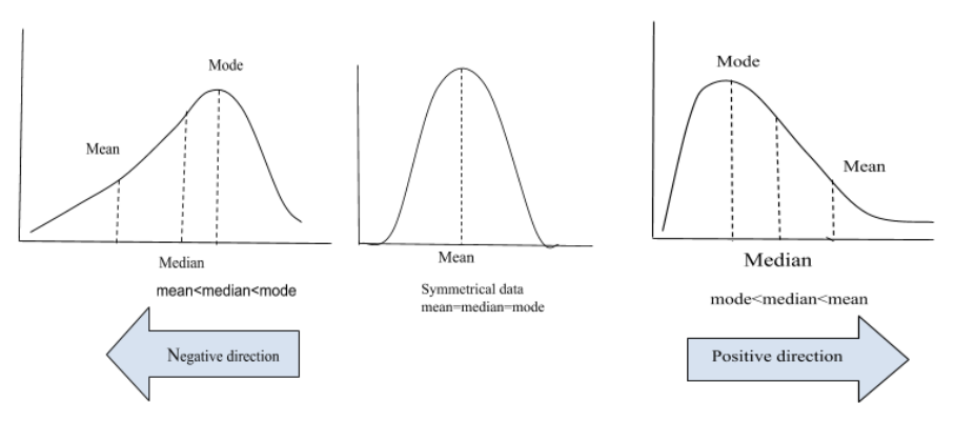
데이터가 정규분포를 따른다면 z-score 방법으로, 정규분포가 아닐경우(왜도가 있거나, 비대칭적이라면) IQR방법으로
IQR(사분위범위)
데이터의 중앙 50%를 나타내는 지표
Q1(1사분위)와 Q3(3사분위) 사이의 범위

- Q1: 데이터의 하위 25%에 해당하는 값 `Q1 = df['컬럼명'].quantile(0.25)`
- Q3: 데이터의 하위 75%에 해당하는 값 `Q3 = df['컬럼명'].quantile(0.75)`
- IQR = Q3 - Q1
#이상치 경계값 설정
minimum(lower_bound) = Q1 - 1.5 * IQR
maximum(upper_bound) = Q3 + 1.5 * IQR
#이상치 제거
df_no_outlier = df[(df['컬럼명'] >= lower_bound) & (df['컬럼명'] <= upper_bound)]Z-score
데이터가 평균으로부터 얼마나 떨어져 있는지를 표준편차 단위로 나타내는 값.
➡️특정 값이 전체 데이터에서 얼마나 극단적인지를 판단하는데 사용됨
# z-score 기반 이상치 제거 모듈 설치
from scipy import stats
import numpy as np
# Z-Score 계산
z_scores=stats.zscore(df['컬럼명'])
# 이상치 경계값 설정
df_no_outliers=df[(z_scores < 3) & (z_scores > -3)] #ver1
df_no_outliers=df[np.abs(z_scores)<3] #ver2
# 이상치 개수 확인
outlier_count = (np.abs(z_score) > 3).sum()
`np.abs(z_score) > 3` 는True(1) / False(0)의 형태로 값이 출력
>> 개수를 알고 싶다면 sum()을 사용
이상치 대체(평균)
# 이상치 대체 (평균)
import numpy as np
# 이상치가 아닌 값들의 평균 계산 (IQR사용)
mean_value = df[(df['컬럼명'] >= lower_bound) & (df['컬럼명'] <= upper_bound)['컬럼명'].mean()
# 이상치를 평균값으로 대체
df['컬럼명'] = np.where((df['컬럼명'] < lower_bound) | (df['컬럼명'] > upper_bound), mean_value, df['컬럼명'])
mean_value
- 이상치가 아닌 것들을 필터링 `df[(df['컬럼명'] >= lower_bound) & (df['컬럼명'] <= upper_bound)`
- 필터링된 데이터 프레임중에서 특정 컬럼만 선택해서 평균을 계산 `df_filtered['컬럼명'].mean()`
np.where(조건, True, False)
조건을 만족하는 요소의 위치를 반환해서 지정한 값으로 반환
- 이상치를 평균값으로 대체할 것이기 때문에, 이상치를 조건으로 설정 ( | : or)
- 이상치이면 mean_value(이상치가 아닌 값들의 평균), 이상치가 아니면 기본 데이터값으로 반환
이상치 대체(이전값, 이후값) - 시계열 데이터
#이전값 대체
df['value'] = df['value'].where((df['value'] <= lower_bound) | (df['value'] >= upper_bound)).fillna(method='ffill') #ver2
❓np.where대신 df['컬럼명'].where을 쓰는 경우
np.where()도 사용가능하지만, df.where()은 기존 데이터 프레임의 구조를 유지하면서 조건을 만족하는 값에만 적용하기 때문에 시계역 데이터를 다룰 때 더욱 안정성있게 사용가능함.
범주화
# 구간을 나누어 범주화후 라벨링
ages = [15, 23, 35, 42, 19, 28, 33, 51, 62, 18, 20, 41]
bins=[0,20,40,60,80]
labels=['청소년', '청년', '중년', '장년']
age_groups = pd.cut(ages,bins=bins, labels=labels)
age_groups
#결과
['청소년', '청년', '청년', '중년', '청소년', ..., '중년', '장년', '청소년', '청소년', '중년']
- bins: 범주의 끝과 시작을 포함 ▶ 나누고자 하는 범주의 개수보다 +1
- labels = 각 구간의 이름
각 구간을 인덱스로 변환
agegroup_idx = np.digitalize(ages,bins)
agegroup_idx
#결과
array([1, 2, 2, 3, 1, 2, 2, 3, 4, 1, 2, 3])정규화
데이터의 범위가 심하게 차이나는 경우, 상대적 특성이 반영된 데이터로 변환하는 과정
🌟컬럼마다 단위가 다른 경우, 정규화를 고려해볼 필요가 있음
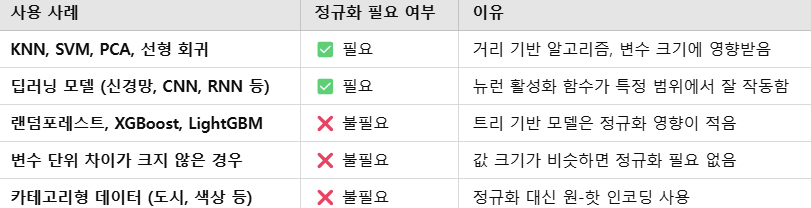
정규화의 종류
- 일반 정규화: 수치로 된 값에 대해서 동일한 수치로 변환
- Min-Max정규화: 최소값은 0, 최대값은 1, 그 외 값은 0과 1사이의 값으로 변환
- Z-score 정규화: 평균은 0, 편차가 1인 정규분포의 데이터로 변환
- 로그 변환: 데이터분포의 형태에서 꼬리가 오른쪽으로 기울어진 경우에, 데이터를 로그데이터로 변환시키며 정규화
- 역수변환: 데이터분포의 형태에서 꼬리가 극단적으로 오른쪽으로 기울어진 경우 에, 데이터를 역수로 변환시키며 정규화
- 제곱근(루트) 변환: 데이터 분포의 형태에서 꼬리가 오른쪽으로 치우친 경우에, 데이터를 제곱근 데이터로 변환하며 정규화
- 지수변환: 데이터분포의 형태에서 꼬리가 왼쪽으로 기울어진 경우 에, 데이터를 지수로 변환시키며 정규화

1. Min-Max Scaling(최소-최대 정규화) - MinMaxScaler
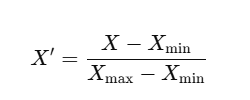
- X: 원래 데이터 값
- Xmin: 해당 컬럼의 최솟값
- Xmax: 해당 컬럼의 최댓값
- X1: 정규화된 값(0~1 범위)
✔️ 데이터가 고르게 분포되어있을 때 적합.
✔️ 최댓값과 최솟값에 영향을 받기 때문에 이상치에 매우 민감
# Min-Max 정규화 ver1
df['Min_Max_Scaled'] = (df['Value'] - df['Value'].min()) / (df['Value'].max() - df['Value'].min())
# Min-Max 정규화 ver2
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df['Normalized'] = scaler.fit_transform(df[['Value']])
2. Z-Score Normalization(표준화) - StandardScaler

- μ: 평균값
- : 표준편차
✔️ 데이터가 정규분포를 따를 때 효과적
❓데이터가 정규분포를 따르는데 왜 표준화를 해야할까?
→ 컬럼마다 각각 다른 단위를 가진 정규분포일수도
✔️ 극단적이 값이 있어도, 데이터의 상대 위치를 유지함
✔️ 거리 기반 모델에서 변수 크기의 차이를 보정하는데에 많이 사용됨
# z-score 정규화 ver1
df['Z_Score_Scaled'] = stats.zscore(df['Value'])
# z-score 정규화 ver2
from sklearn.preprocessing import StandardScaler
# Z-Score 표준화 적용
scaler = StandardScaler()
df['Standardized'] = scaler.fit_transform(df[['price']])#여러 컬럼에 z-score정규화를 적용하는 경우- ver1
df_zscore = df.apply(stats.zscore)
#결과
A B
0 -1.414214 -1.414214
1 -0.707107 -0.707107
2 0.000000 0.000000
3 0.707107 0.707107
4 1.414214 1.414214
#여러 컬럼에 z-score정규화를 적용하는 경우- ver2
df_zscore = stats.zscore(df)
#결과
[[-1.414214 -1.414214]
[-0.707107 -0.707107]
[ 0.000000 0.000000]
[ 0.707107 0.707107]
[ 1.414214 1.414214]]- `df.apply(stats.zscore)` : 각 컬럼을 개별적으로 Pandas DataFrame으로 변환 ✅권장
- `stats.zscore(df)` : 전체 DateFrame을 Numpy배열로 변환 → 후처리가 필요할 수도 있음.
3. Robust Scaling

중앙값과 IQR을 사용해서 이상치에 영향을 덜 받도록 하는 정규화
✔️ 이상치에 영향을 덜 받음
✔️ 데이터가 정규분포가 아닐 때에도 효과적
➡️ 이상치가 많은 금융데이터나, 지진강도와 같은 데이터에 적용하기에 적합
4. 로그 변환(Log Transformation)
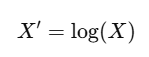
✔️ 값이 큰 경우에 효과적
✔️ 음수 값이나 0이 포함되면 적용할 수 없음.
df['Log_price'] = np.log(df['price'])5. 역수 변환(Reciprocal Transformation)

데이터 값을 역수로 변환해서 분포를 조정하며 정규화
✔️ 오른쪽으로 기울어짐을 완화
✔️ 값이 클수록 변환 후에는 작은 값이 됨
✔️ 0이 포함되면 적용 불가
✔️ 데이터가 비선형인 경우에 활용
df['Inverse_Value'] = 1 / df['Value']5. 제곱근 변환(Square Root Transformation)

✔️ 오른쪽 치우친 데이터 정규화
✔️ 값이 클수록 더 큰 영향을 받는다.
✔️ 로그 변환보다 완만하게 변형한다.
✔️ 음수 적용 x
df['SquareRoot_Value'] = np.sqrt(df['Value'])6. 지수 변환(Exponential Transformation)
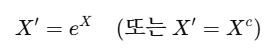
데이터에 지수(exp)를 적용해서 분포를 조정하는 방법
로그 변환과는 반대 역할
✔️왼쪽 치우침 완화
✔️ 데이터의 값이 작을수록 더 빠르게 증가
✔️ 값이 커질수록 데이터가 급격히 증가해서 이상치가 강조될 수도 있음.
df['Exp_Value'] = np.exp(df['Value'])
df['Squared_Value'] = np.power(df['Value'], 2)
df['Squared_Value'] = np.power(df['Value'], 3)
인코딩
문자형 데이터를 숫자로 변환하는 과정
머신러닝 모델은 숫자데이터만을 처리하기 때문에, 범주형 데이터를 수치형 데이터로 변환하는 과정을 거쳐야함.
- 레이블 인코딩: 각 카테고리 를 정수로 변환
- 원-핫 인코딩: 각 카테고리를 0과 1로 변환
- 타깃 인코딩: 각 카테고리에 대한 종속변수를 평균값으로 변환, 분류문제에 주로 활용되며, 과적합 가능성이 있음
✔️ 순서(크기)가 없는 범주형 데이터의 인코딩 방식: 원-핫 인코딩
✔️ 순서(크기)가 있는 범주형 데이터의 인코딩 방식: 레이블 인코딩, 순서 인코딩
1. 레이블 인코딩(Label Encoding)
각 카테고리에 고유한 정수를 할당하는 방식
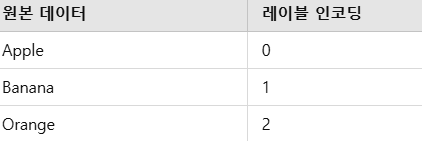
✔️ 카테고리형 데이터를 정수로 변환하는 경우에 사용
✔️ 하지만, 순서 관계가 생길 위험이 있다.
예를 들어 모델은 apply < banana < orange와 같은 서열로 인식할 수 있음.
➡️ 원-핫 인코딩 사용
#범주를 지정된 라벨로 변환 -ver1
category_mapping={'Low' : 0, 'Medium':1, 'High':2}
df['Category_Encoded']=df['Category'].map(category_mapping)
#라벨 인코딩-ver2
from sklearn.preprocessing import LabelEncoder
fruits = ['Apple', 'Banana', 'Orange', 'Banana', 'Apple']
encoder = LabelEncoder()
encoded_labels = encoder.fit_transform(fruits)
print(encoded_labels)
#결과
[0 1 2 1 0]
2. 원-핫 인코딩(One-Hot Encoding)
각 카테고리를 0과 1의 벡터로 변환하는 방식

✔️ 각 카테고리가 개별적인 컬럼이 되고, 값이 있으면 1, 없으면 0으로 출력된다.
✔️ 순서 정보가 없어 각 카테고리가 독립적으로 표현된다.
✔️ 카테고리 개수가 많아지면 차원이 증가해 문제가 발생함.
Ver1. - get_dummies활용
#One-Hot encoding ver1
import pandas as pd
# 예제 데이터
df = pd.DataFrame({'Fruit': ['Apple', 'Banana', 'Orange', 'Banana', 'Apple']})
# One-Hot Encoding 적용
df_one_hot = pd.get_dummies(df, columns=['Fruit'])
print(df_one_hot)
Fruit_Apple Fruit_Banana Fruit_Orange
0 1 0 0
1 0 1 0
2 0 0 1
3 0 1 0
4 1 0 0
Ver2. - OneHotEncoder()사용
#One-Hot encoding ver2
# OneHotEncoder 객체 생성
encoder = OneHotEncoder(sparse=False) # sparse=False로 하면 배열 형태로 결과를 반환
# 데이터를 fit_transform()을 통해 변환
encoded_data = encoder.fit_transform(df[['Category']]).toarray()
# 결과를 DataFrame으로 변환
encoded_df = pd.DataFrame(encoded_data, columns=encoder.get_feature_names_out(['Category']))
# 원본 DataFrame과 인코딩된 DataFrame을 합침
df = pd.concat([df, encoded_df], axis=1)
print(encoded_df)
#결과
Fruit Fruit_Apple Fruit_Banana Fruit_Orange
0 Apple 1.0 0.0 0.0
1 Banana 0.0 1.0 0.0
2 Orange 0.0 0.0 1.0
3 Banana 0.0 1.0 0.0
4 Apple 1.0 0.0 0.0
❗pandas의 get_dummies()는 직관적이고 빠르게 One-Hot Encoding 적용 가능
❗sklearn의 OneHotEncoder()는 머신러닝 파이프라인에서 사용하기 적합하다.
Numpy배열로 출력되기 때문에 후처리가 필요하다는 번거로움이 있음
3. 순서 인코딩(Ordinal Encoding)
서열(순서)이 있는 범주형 데이터를 숫자로 변환하는 방식

✔️ 잘못 사용하면 모델이 순서정보를 잘못해석할 수 있기 때문에 순서 관계를 유지해야하는 경우에만 적합
from sklearn.preprocessing import OrdinalEncoder
#예제 데이터
df = pd.DataFrame({'Size': ['Small', 'Medium', 'Large', 'Medium', 'Small']})
#순서형 인코딩 적용
encoder=OrdinalEncoder(categories=[['Small', 'Medium', 'Large']]) #순서지정
df['Size_Encoded']=encoder.fit_transform(df[['Size']])
4. 타켓인코딩(Target Encoding)
분류모델에서 카테고리별 타겟값의 평균을 사용해서 인코딩
예제 데이터

카테고리별 평균 구매율 계산
- A: (1+0+1)/3=0.67(1+0+1)/3 = 0.67
- B: (1+1)/2=1.00(1+1)/2 = 1.00
- C: (0)/1=0.00(0)/1 = 0.00
인코딩 결과

import pandas as pd
# 원본 데이터
df = pd.DataFrame({
'Category': ['A', 'A', 'A', 'B', 'B', 'C'],
'Purchase': [1, 0, 1, 1, 1, 0] # 타겟 변수 (구매 여부)
})
# 타겟 인코딩 적용 (카테고리별 평균 계산)
df['Category_Encoded'] = df.groupby('Category')['Purchase'].transform('mean')'TIL - today I learned' 카테고리의 다른 글
| [멋쟁이사자처럼 데이터분석 부트캠프] 머신러닝 - KNN (0) | 2025.02.23 |
|---|---|
| [멋쟁이사자처럼 데이터분석 부트캠프] 머신러닝 개요 (0) | 2025.02.22 |
| [멋쟁이사자처럼 데이터분석 부트캠프] - EDA # 불균형 데이터 처리(오버샘플링&언더샘플링) (0) | 2025.02.18 |
| [멋쟁이사자처럼 데이터분석 부트캠프] - EDA #데이터 병합 #상관관계 #차원축소(PCA) (0) | 2025.02.17 |
| [멋쟁이사자처럼 데이터분석 부트캠프] - EDA #데이터 로드 #데이터 개요 확인 (0) | 2025.02.10 |